6.4.10 YOLO-World Object Detection
Last Version: 12/09/2025
This guide demonstrates how to use the YOLO-World model for Open-Vocabulary object detection on SpacemiT computing hardware. You'll learn to run inference on both images and video streams, visualize the results, and process the detection data through ROS 2 topics.
YOLO-World Model Overview
YOLO-World is an open-vocabulary, zero-shot object detection model developed by Tencent AI Lab. First introduced in early 2024, it combines:
- The fast and efficient YOLO architecture (based on Ultralytics YOLOv8)
- Vision-language fusion technology
- Ability to detect objects described by arbitrary text prompts without category-specific training
Environment Setup
Install Dependencies
sudo apt install python3-venv python3-pip ros-humble-camera-info-manager \
ros-humble-image-transport python3-spacemit-ort
Source ROS2 Environment
source /opt/bros/humble/setup.bash
Set Up Python Virtual Environment
python3 -m venv ~/test3
source ~/test3/bin/activate
pip install -r /opt/bros/humble/share/jobot_yolo_world/data/requirements.txt
Update the Python path
export PYTHONPATH="$HOME/test3/lib/python3.12/site-packages":$PYTHONPATH
Image-Based Object Detection
Prepare a Test Image
cp /opt/bros/humble/share/jobot_yolo_world/data/test2.jpg .
Run Inference and Save Results Locally
ros2 launch br_perception yoloworld_infer_img.launch.py \
img_path:='./test2.jpg' \
class_names:="[fan, box]"
The detection results are saved as yoloworld_result.jpg in the current directory.

Terminal output shows detection details:
(test3) bianbu@bianbu:~$ ros2 launch br_perception yoloworld_infer_img.launch.py img_path:='./test2.jpg' class_names:="[fan, box]"
[INFO] [launch]: All log files can be found below /home/bianbu/.ros/log/2025-08-13-16-09-04-608187-bianbu-217760
[INFO] [launch]: Default logging verbosity is set to INFO
[INFO] [yoloworld_img_node-1]: process started with pid [217761]
[yoloworld_img_node-1] /home/bianbu/test3/lib/python3.12/site-packages/clip/clip.py:6: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
[yoloworld_img_node-1] from pkg_resources import packaging
[yoloworld_img_node-1] All model files already exist and do not need to be downloaded
[yoloworld_img_node-1] conf_threshold: 0.2, iou_threshold: 0.45, class_names: ['fan', 'box']
[yoloworld_img_node-1] Init Model ..................
[yoloworld_img_node-1] all time cost:0.697995662689209
[yoloworld_img_node-1] x_min:980, y_min:469, width:466, height:424, label:box, confidence:0.72
[yoloworld_img_node-1] x_min:417, y_min:510, width:294, height:493, label:fan, confidence:0.29
[yoloworld_img_node-1] The object detection results are saved in: det_result.jpg
[INFO] [yoloworld_img_node-1]: process has finished cleanly [pid 217761]
Web-Based Visualization
Terminal 1 - Start inference node:
ros2 launch br_perception yoloworld_infer_img.launch.py \
publish_result_img:=true \
img_path:='./test2.jpg' \
class_names:="[fan, box]"
Terminal 2 - Launch web visualization:
ros2 launch br_visualization websocket_cpp.launch.py image_topic:='/result_img'
The terminal will print the message as:
...
Please visit in your browser: http://<IP>:8080
...
Open a browser and visit the URL shown in the terminal (e.g., http://<IP>:8080) to view results:
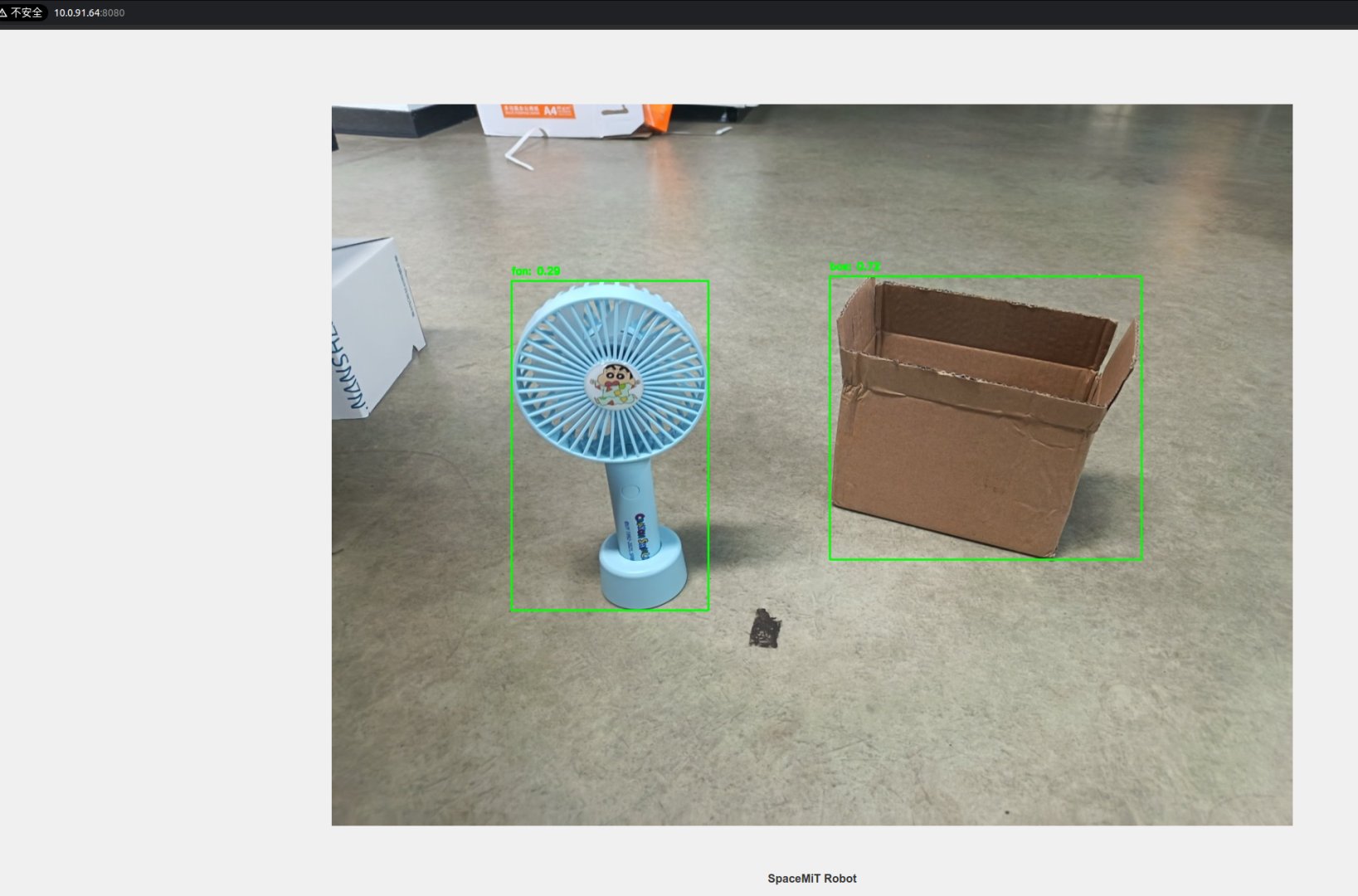
Subscribe to Results
To view the inference results by
ros2 topic echo /inference_result
Or use this Python script to subscribe to inference results:
from rclpy.node import Node
from std_msgs.msg import Header
from jobot_ai_msgs.msg import DetectionResultArray, DetectionResult
import rclpy
class DetectionSubscriber(Node):
def __init__(self):
super().__init__('detection_sub')
self.subscription = self.create_subscription(
DetectionResultArray,
'/inference_result',
self.listener_callback,
10)
def listener_callback(self, msg: DetectionResultArray):
self.get_logger().info(f"Frame: {msg.header.frame_id}")
for det in msg.results:
self.get_logger().info(
f"[{det.label}] ({det.x_min},{det.y_min}) "
f"{det.width}x{det.height} conf={det.conf:.2f}"
)
def main(args=None):
rclpy.init(args=args)
node = DetectionSubscriber()
rclpy.spin(node)
node.destroy_node()
rclpy.shutdown()
main()
Parameters Description
yoloworld_infer_img.launch.py Parameters
| Parameter | Description | Default Value |
|---|---|---|
img_path | Path to the input image for detection | data/detection/test.jpg |
publish_result_img | Whether to publish detection results as an image message | false |
result_img_topic | Topic name for published image results (if publish_result_img = true) | /result_img |
result_topic | Topic name for published detection results | /inference_result |
conf_threshold | Minimum confidence score for detections (filters low-confidence boxes) | 0.2 |
iou_threshold | Threshold for removing overlapping detections (handles overlapping boxes) | 0.45 |
class_names | Target objects to detect (can be categories or natural language descriptions) | ["people"] |
Video Stream Inference
Start USB Camera
ros2 launch br_sensors usb_cam.launch.py video_device:="/dev/video20"
Run Inference & Publish results
Terminal 1 - Start inference:
ros2 launch br_perception yoloworld_infer_video.launch.py \
sub_image_topic:='/image_raw' \
publish_result_img:=true \
result_topic:='/inference_result' \
class_names:="[box]"
Terminal 2 - Launch web visualization:
ros2 launch br_visualization websocket_cpp.launch.py image_topic:='/result_img'
The terminal will print the message as:
...
Please visit in your browser: http://<IP>:8080
...
Open a browser and visit the URL shown in the terminal (e.g., http://<IP>:8080) to view results.
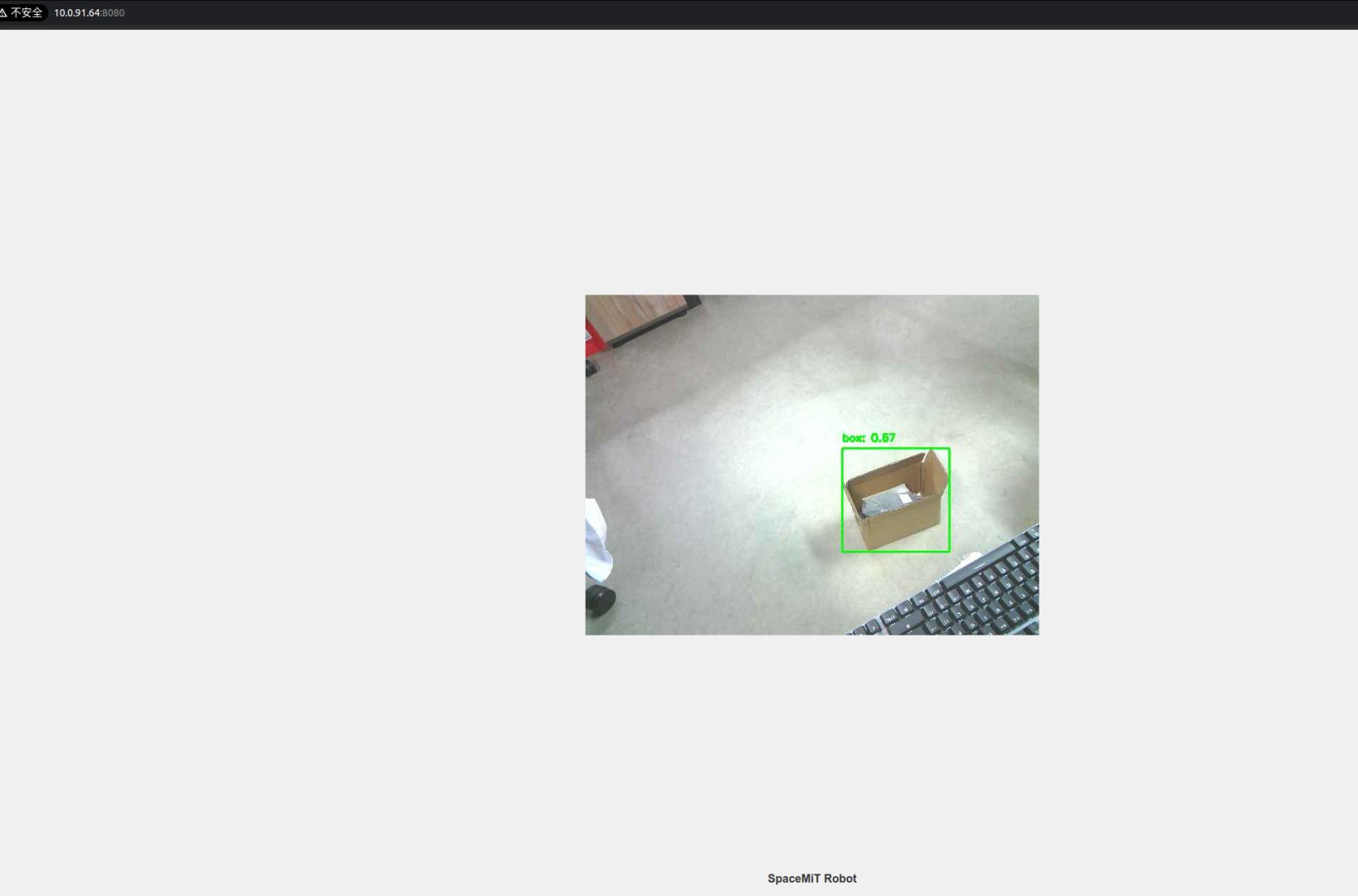
Data-Only Inference (No Visualization)
If you only want to obtain the model inference results, run the following command:
ros2 launch br_perception yoloworld_infer_video.launch.py \
sub_image_topic:='/image_raw' \
publish_result_img:=false \
result_topic:='/inference_result' \
class_names:="[box]"
Subscribe to Results
To view the inference results by
ros2 topic echo /inference_result
Or use this Python script to subscribe to inference results:
from rclpy.node import Node
from std_msgs.msg import Header
from jobot_ai_msgs.msg import DetectionResultArray, DetectionResult
import rclpy
class DetectionSubscriber(Node):
def __init__(self):
super().__init__('detection_sub')
self.subscription = self.create_subscription(
DetectionResultArray,
'/inference_result',
self.listener_callback,
10)
def listener_callback(self, msg: DetectionResultArray):
self.get_logger().info(f"Frame: {msg.header.frame_id}")
for det in msg.results:
self.get_logger().info(
f"[{det.label}] ({det.x_min},{det.y_min}) "
f"{det.width}x{det.height} conf={det.conf:.2f}"
)
def main(args=None):
rclpy.init(args=args)
node = DetectionSubscriber()
rclpy.spin(node)
node.destroy_node()
rclpy.shutdown()
main()
Parameters Descriptions
yoloworld_infer_video.launch.py Parameters
| Parameter | Description | Default Value |
|---|---|---|
sub_image_topic | Topic name for the input image | /image_raw |
publish_result_img | Whether to publish detection results as an image message | false |
result_img_topic | Topic name for published image results (if publish_result_img = true) | /result_img |
result_topic | Topic name for published detection results | /inference_result |
conf_threshold | Minimum confidence score for detections (filters low-confidence boxes) | 0.2 |
iou_threshold | Threshold for removing overlapping detections (handles overlapping boxes) | 0.45 |
class_names | Target objects to detect (can be categories or natural language descriptions) | ["people"] |